

Today we have two very exciting things to share:
- We are open sourcing Parca: An open source continuous profiling storage, query engine and an eBPF based profiler.
- We raised a $4M seed from GV & Lightspeed, as well as an amazing line up of angel investors!
Our journey
Several of us at Polar Signals are long term Prometheus, Thanos, Cortex and Kubernetes contributors and maintainers. In the last couple of years these projects have had an incredible growth, and while working on these projects, we noticed a gap in the ecosystem — a tool that we could have used very well ourselves while working on these projects — an open source continuous profiling that integrates well with the hundreds of thousands of Prometheus & Kubernetes deployments worldwide.
At KubeCon 2019, Tom Wilkie and I were given the opportunity to share on the keynote stage what we believed was next for the observability space. I predicted that continuous profiling was going to become an area of innovation and shared a proof of concept that I creatively named Conprof (CONtinuous PROFiling).
At the end of last year I founded Polar Signals to pursue continuous profiling full time, I immediately recalled a conversation I had with Thor at GopherCon 2018, he said: “If you ever create an Observability company, I’ll be the first to join you!” - and so he did. Matthias and I have worked together in the Prometheus ecosystem for several years, and when Polar Signals was announced he reached out to discuss how he could be a part of it — and thus, the team was born. Since then Kemal and Sumera have also joined the ride. We quickly had VCs offer to fund us, but we felt we had to explore the space further and launch our private beta.
We launched our private beta in February to work with early users and understand more intimately where we needed to take the technology, product and company. A few months into working with early users there was the turning point at which we understood what we needed to do, and after a few weeks of fundraising we couldn’t be happier to have partnered with GV and Lightspeed (and an incredible line up of angel investors).
Taking a step back from continuous profiling, we feel that the Observability space has, in a way, lost itself, users are overwhelmed with mountains of information and are unable to cut through the noise and actually answer the questions they have. Our mission at Polar Signals is to take the observability space forward and not just observe and store data, but to actually understand it. We want to take observability to understandability. With continuous profiling we are taking the first step towards achieving this goal, we are helping users truly understand what their running code is doing, and therefore help to optimize it.
Open Source Parca
Open source is part of our identity at Polar Signals, and staying true to ourselves, today, we are introducing Parca, an umbrella project that is home to a storage, optimized to store and query profiling data as well as a super low overhead eBPF based profiler. In true open source spirit we have always chosen the open pprof format for profiling data to allow best possible compatibility with the ecosystem, so any profiler that can produce pprof formatted profiles is already compatible with Parca.
The name Parca plays on the Program for Arctic Regional Climate Assessment (PARCA) and the practice of ice core profiling that has been done as part of it studying climate change. With the open source Parca project we intend to democratize continuous profiling and contribute a little towards preventing climate catastrophe.
The eBPF profiler, Parca Agent, discovers targets to capture CPU profiles from (and other types in the future), using either Kubernetes or SystemD, so an entire infrastructure can automatically be profiled - without requiring restarts or change of deployment of any application. Using the metadata from Kubernetes and SystemD, the series of profiles are labelled identically to Prometheus time-series, intended to maximize the utility of combining Parca with a Prometheus setup. Once written to the Parca storage, the data can be sliced and diced using label-selectors, exactly the same way as in Prometheus.
What can I do with Parca and continuous profiling?
Continuous profiling enables us to answer questions that are either impossible or incredibly difficult to answer without it. Let’s look at the three most common use cases we have found people to want a continuous profiling tool for:
- Save infrastructure cost
- Optimize specific interactions
- Understand change
Save infrastructure cost
Saving on infrastructure cost has very clear implications, if a software engineer can find out where the biggest optimization potential lies, then they can focus improvements towards it. One-off profiling can work for this, but there are various problems with this:
- One-off profiling is not reflective of the entire infrastructure, only of the one process being profiled. At most, using perf one host can be profiled and analyzed, but not across servers.
- One-off profiling is only a point in time analysis, it is not reflective of the entirety of the process. It is not statistically significant.
To solve these problems, Parca allows merging a time-range of profiles into a single report ensuring an infrastructure-wide and statistically sound. Visualized via icicle-graphs (the upside-down version of flamegraphs).
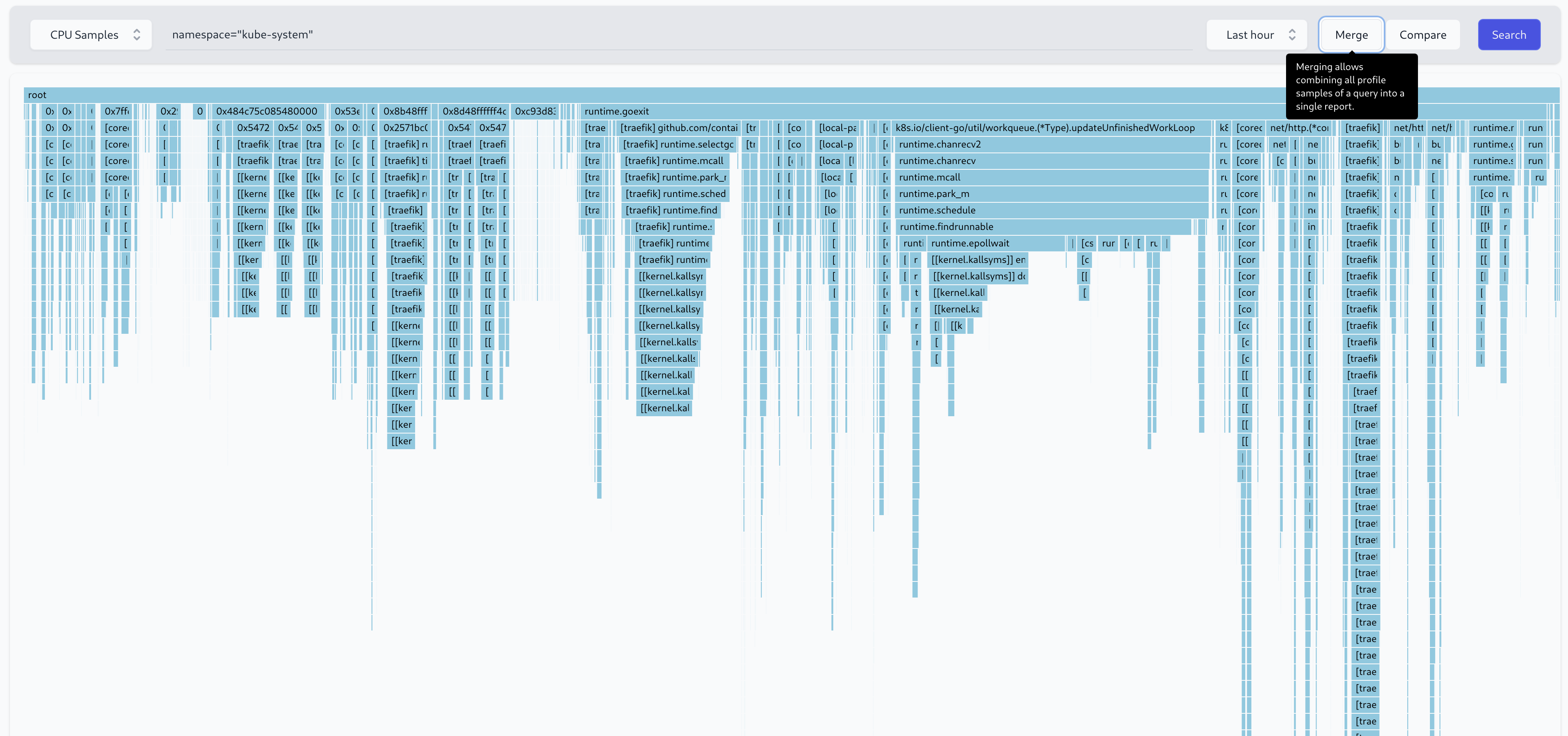
Optimize specific interactions
Early in our exploration of continuous profiling we realized that practically every user first uses a metrics system to pin-point certain time-frames to investigate first and then pull up a profile according to it. To make this search efficient, Parca allows graphing the total value of the profiles over time, and selecting individual profiles of a point in time within it. That way a spike in memory of the CPU for example can immediately be pulled up. Without continuous profiling and Parca we would have to hope to profile our software at exactly the right time, which more often than not results in a search for the needle in the haystack.
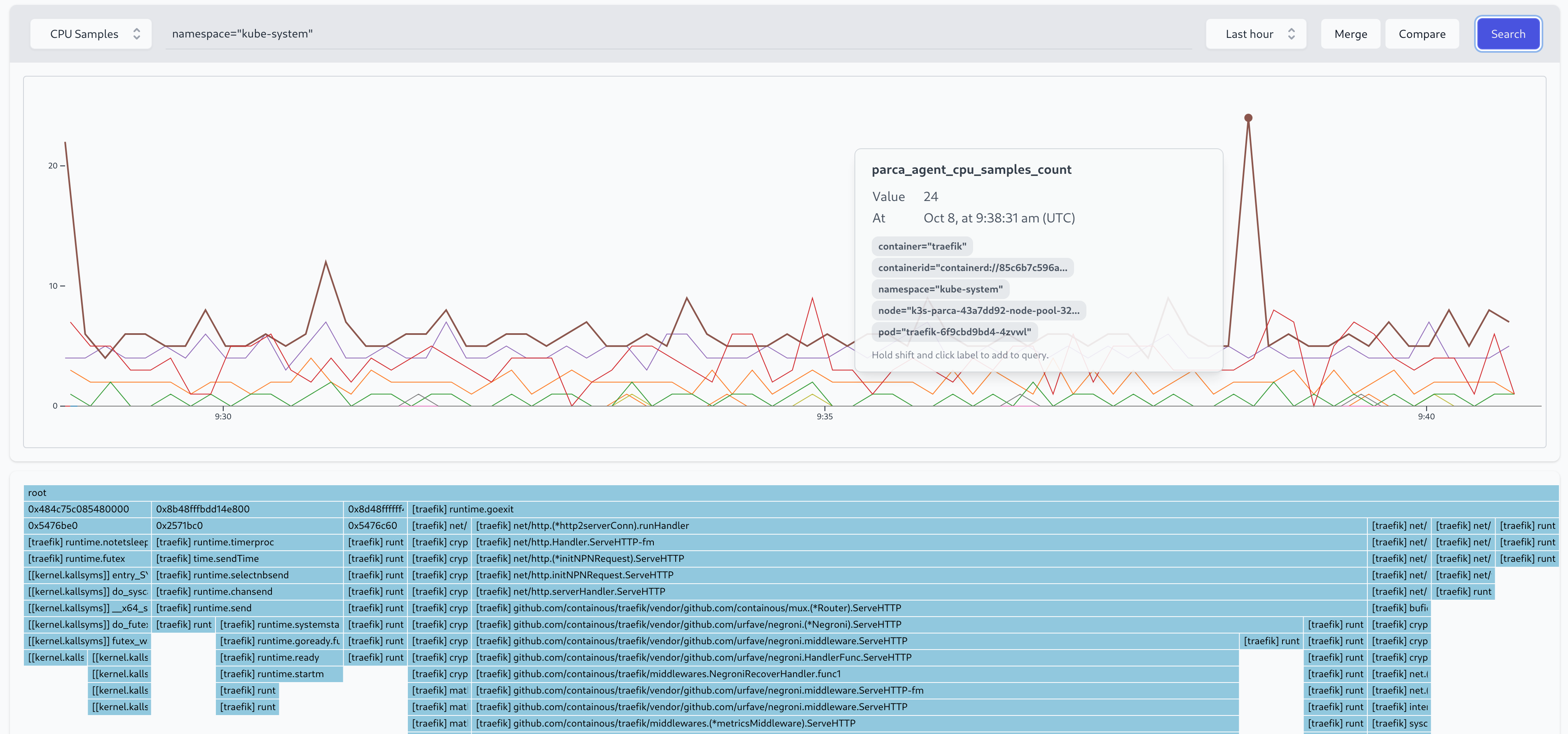
Understand change
An incredibly difficult thing to understand without continuous profiling is how performance characteristics change over time. Profiles need to be captured in the first place to be able to do it, and much like with other observability data, you never know what data you are going to need - so you need all of it throughout time.
More importantly, it needs to be possible to visualize change, we found differential icicle-graphs to reflect our mental model of code execution best. We can precisely answer the question of:
- What was different between two points in time?
- What is the difference before and after a rollout of a deployment?
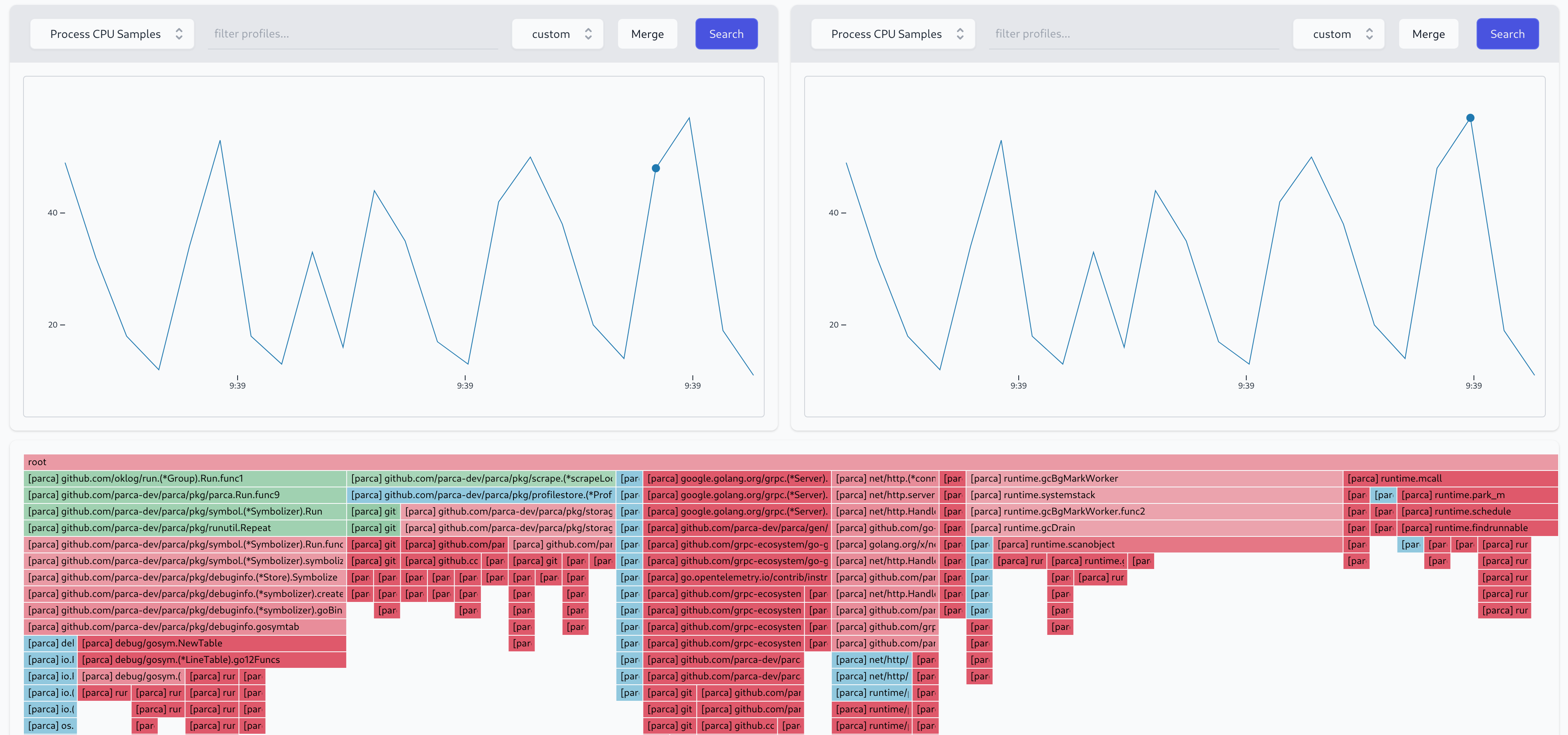
Wrapping up
This is only the beginning of the Parca project, and we wanted to share it as soon as possible to shape the project together with the community. If you like Parca, head over to GitHub and give it a star, contribute, try it out and file issues!
If you are interested in further details, check out the Parca website as well as our upcoming talks at KubeCon North America 2021:
- Wednesday, October 13 11:00am - 11:35am Cloud-Native and Kubernetes Observability Panel: The State of Union - Bartek Plotka, Red Hat; Liz Fong-Jones, Honeycomb; Josh Suereth, Google; Frederic Branczyk, Polar Signals; Rags Srinivas, InfoQ
- Parca - Profiling in the cloud-native era - Matthias Loibl & Kemal Akkoyun (Friday, October 15 4:30pm - 5:05pm)
- Beyond the Hype: Cloud Native eBPF - Frederic Branczyk (Friday, October 15 5:25pm - 6:00pm)
We are using the investment to grow the technology and our team: we are hiring! Thank you to our investors and amazing line up of angels for their trust and support!