2022 was an incredibly busy year at Polar Signals, and for the Parca project. In this blog post we’re going to look back at some of our favorite features and improvements that have been released in the last couple of months, that we haven’t already featured in other blog posts.
Parser-based autocomplete (released in Parca v0.14.0)
The truth is the Parca UI always had an Earley parser (based on the incredible nearley.js project) for the query language, but this parser was not used for autocompletion purposes yet, only to understand the query and add things to the query, such as when clicking onto a label. Now, based on the query already typed, the parser predicts the next possibly valid things to type and suggests them if possible. It can also recognize, if a label-name or label-value is being typed, and suggests a type-ahead using available, known-to-exist values.
Typing a query in Parca's web UI guided by autocomplete.
Filter by Function (released in Parca v0.15.0)
Sometimes you already know what we are looking for, as for example you’ve been optimizing a function, rolled out a change to production and now want to know if the improvement had the effect you want. But this may be a function that in the grand scheme of things does not make up the majority of CPU time, an API call that is not called all the time, but is latency sensitive could be a good example. In fact we have this in Polar Signals Cloud very frequently. The majority of resources are spent in ingesting data, as that happens all the time, while querying data is rather rare in comparison, but we still want queries to complete quickly.
Find extended documentation and more example usages in the dedicated docs page: https://www.parca.dev/docs/filter-by-function.
Filtering profiling data by partial function name.
Parca Agents in Targets Page (released in Parca v0.13.0)
Before this feature it was difficult to tell whether Parca Agents were sending data to a Parca server. Now any Parca Agent that has successefully sent data in the last 15 minutes will show up on the targets page (available on /targets on any Parca web UI).
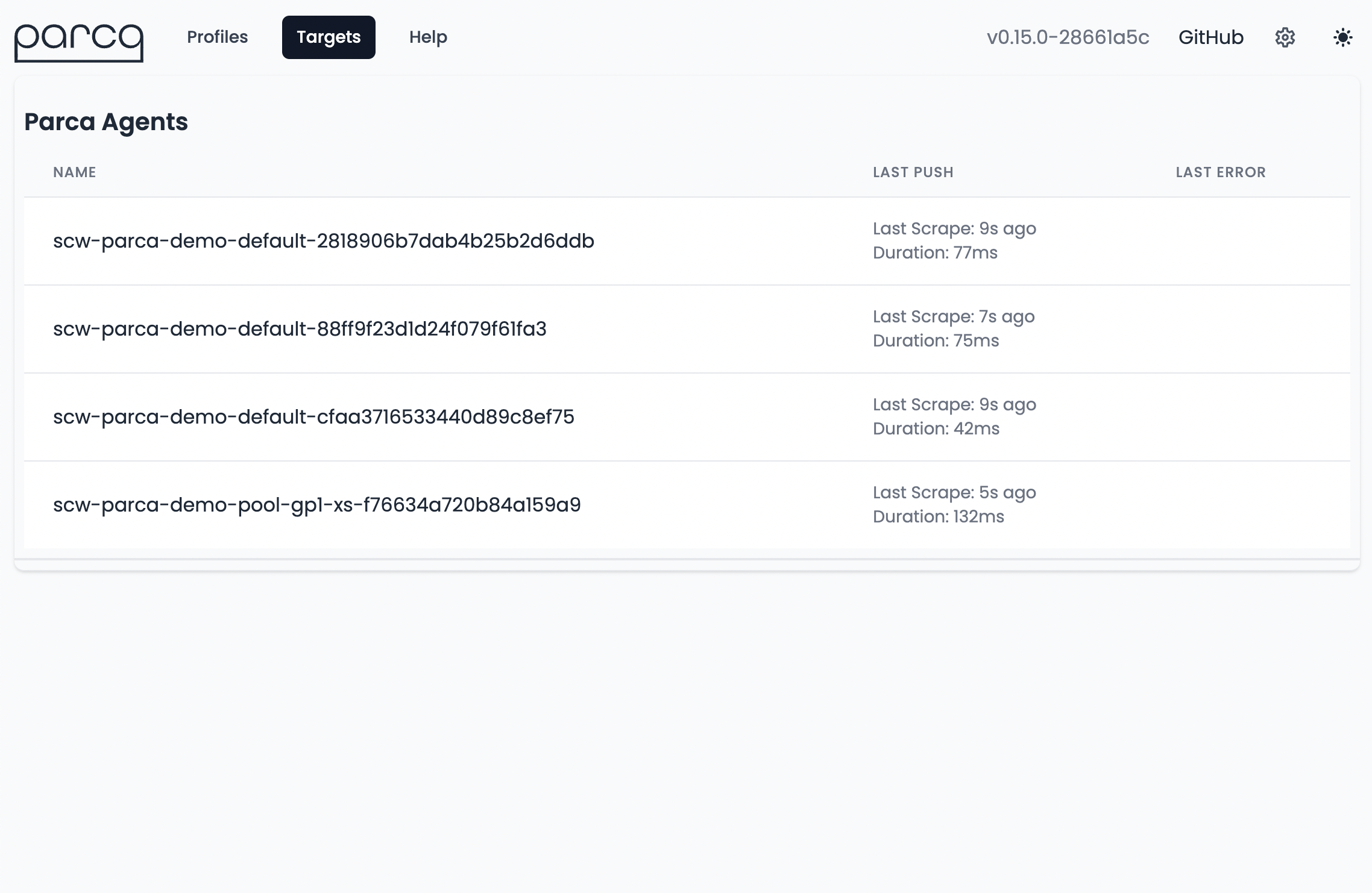
Parca's Targets page showing 4 Parca Agents actively sending data.
Signed Uploads (released in Parca v0.15.0 and Parca Agent v0.11.0)
To most users this will be invisible, but whenever debuginfos from native binaries need to be uploaded (for example when your application is written in C, C++, Rust, Go, etc.), then a Parca server can now opt-in to using their object storage provider’s pre-signed URL feature. This means that an upload will no longer go through Parca’s home-grown gRPC upload API, but rather directly to the object storage provider. This greatly improved the reliability and throughput of uploads, especially with very large binaries.
The debuginfo CLI has also been updated to support signed URL uploads starting in v0.4.0. The debuginfo CLI is useful when production binaries don't contain debuginfos, but they exist elsewhere (most often in the CI pipeline), from where it can be uploaded out-of-band.
Parca Agent Metadata from Whole-System Profiling (Parca Agent v0.10.0)
We’ve previously written about Whole-System Profiling in Parca Agent and why it was implemented. Profiling a lot more processes brought a few new challenges with it, and one of those was: How can people find the data they’re looking for?
We decided to look at it as an opportunity, and tried to find as much metadata about processes as we could. This resulted in Kubernetes metadata being added to processes based on their PID, cgroup information, but even things like which compiler was used to compile a given binary. There are still lots more possibilities to add additional metadata, and we think the more metadata the better.
Find extended documentation and more example usages in the dedicated docs page: https://www.parca.dev/docs/parca-agent-labelling.
Relabeling in Parca Agent (Parca Agent v0.10.0)
There is a lot of influence in the Parca project from the Prometheus project, and relabeling is one of those. I won’t go into details about what relabeling is, as there are plenty of resources on relabeling. There was already relabeling support in the scrape layer of Parca, just like in Prometheus, but this concerns metadata that Parca Agent discovers about a process. This relabelling can be used to either add/change/delete labels from profiling data, or it can be used to selectively send data to Parca. For example if only certain Kubernetes Pod’s profiling data should be sent to Parca, you could use a config like:
relabel_configs:
- source_labels: [pod]
regex: my-webapp-(.+)
action: keepThe `--config-file` flag on Parca Agent is used to tell it where to find that configuration.
Find extended documentation and more example usages in the dedicated docs page: https://www.parca.dev/docs/parca-agent-labelling.
Callgraph (experimental, first PRs landed in v0.13.0)
While still experimental and behind a feature flag as there is still plenty of work left to do, I’m very excited about this feature, so I wanted to showcase it here. Some of you may be familiar with the pprof toolchain, which supports the callgraph visualization using the evergreen graphviz. We felt that this visualization is useful, so we set out to bring it to Parca (while modernizing it a bit). Fun fact, it actually still uses graphviz under the hood to calculate the layout, but a version that is compiled to wasm.
Exploring profiling data using the experimental callgraph visualization.
What should we work on next?
There have been many many more improvements, particularly resource improvements in FrostDB (Parca's embedded columnar database).
What do you think we should work on next? Send us a Tweet, write to us on Mastodon, or join the Parca Discord server to let us know!