A few months ago, we published Part 1 of the Introduction for our favorite open source continuous profiler, Parca. In Part 2, we explore Parca Agent- the eBPF sampling profiler that continuously collects raw profiling data to profile all the processes on a machine.
Parca Agent Quickstart Tutorial
This tutorial covers setting up Parca Agent to fetch stack information for all processes on the system.
Prerequisites:
- Currently, Parca Agent needs a host machine with Linux Kernel v4.18+ to use eBPF functionalities.
- If you are using a Mac, lima-vm can be used to run the Agent. Use the following command to start lima:
limactl start --name=default template://docker-rootful
- A tutorial for using Parca Agent in Kubernetes can be found here
Download the latest server binary release for your architecture from the releases page.
For `amd64` machines:
curl -sL https://github.com/parca-dev/parca-agent/releases/download/v0.11.0/parca-agent_0.11.0_`uname -s`_x86_64.tar.gz | tar xvfz - parca-agent && cd parca-agent
For `arm64` machines:
curl -sL https://github.com/parca-dev/parca-agent/releases/download/v0.11.0/parca-agent_0.11.0_`uname -s`_arm64.tar.gz | tar xvfz - parca-agent && cd parca-agent
To run Parca Agent using docker instead:
docker run --rm -it --privileged --pid host -p 7071:7071 -v /run:/run -v /boot:/boot -v /lib/modules:/lib/modules -v /sys/kernel/debug:/sys/kernel/debug -v /sys/fs/cgroup:/sys/fs/cgroup -v /sys/fs/bpf:/sys/fs/bpf -v /var/run/dbus/system_bus_socket:/var/run/dbus/system_bus_socket ghcr.io/parca-dev/parca-agent:v0.11.0 /bin/parca-agent
The Agent needs to be run as a `root` user (or `CAP_SYS_ADMIN` & `CAP_SYS_RESOURCE` & `CAP_BPF`) to leverage the eBPF capabilities on the host Linux machine. Start `parca agent` with:
sudo ./parca-agent
You should see the Parca agent logs appear so
Parca Agent startup logs
By default, Parca Agent UI is exposed at host port 7071. The host port can be changed by using the `--http-address` flag while starting the Agent.
Note:
To see the stack traces for the profiled processes using the Parca Server UI, the Agent must be started with the `--remote-store-address=7070` flag where `7070` denotes `localhost:7070` which exposes the Parca server. Detailed instructions to run the Parca server can be found here
We can see the Agent running if we navigate to the browser at http://localhost:7071/
Click on Process List in the Processes section to see all the processes profiled by the Agent.
Exploring profiling data in Parca agent.
If you take a closer look at the processes, you will notice several labels associated with each process PID. For example, let's look at a process that calls the `zsh` shell:
These labels expose important metadata for processes, including the process name with `comm`, the executable binary for the process with `executable`, the kernel version, and whether or not the binary has debuginfo intact with the `stripped` label, among others. Additional Kubernetes metadata such as `pod` name is also added for processes running in containers.
The CPU profiler attaches various labels to each PID to not only make process discovery easier for the user but also enable Prometheus-style relabelling to allow the user to customize labels and filter profiles being sent from the Agent to the Parca Server accordingly.
Suppose we want to configure the Agent to send profiles for only processes that run the zsh shell, we can use the following config:
relabel_configs:
- source_labels: [comm]
regex: zsh(.*)
action: keepThe config can be stored in a `YAML` file which can be passed to the Agent using the `--config-file` flag. Expanding the `Content` under the Configuration section will show us the config we passed earlier.
If you expand the `Processes` section, you will notice only the processes with the label `comm = zsh` are present.
More details and examples for relabelling are available in the Parca Agent documentation here
Inside Agent
Now that we have set up Parca Agent to discover all processes on our machine, let us dive deeper into its architecture and components.
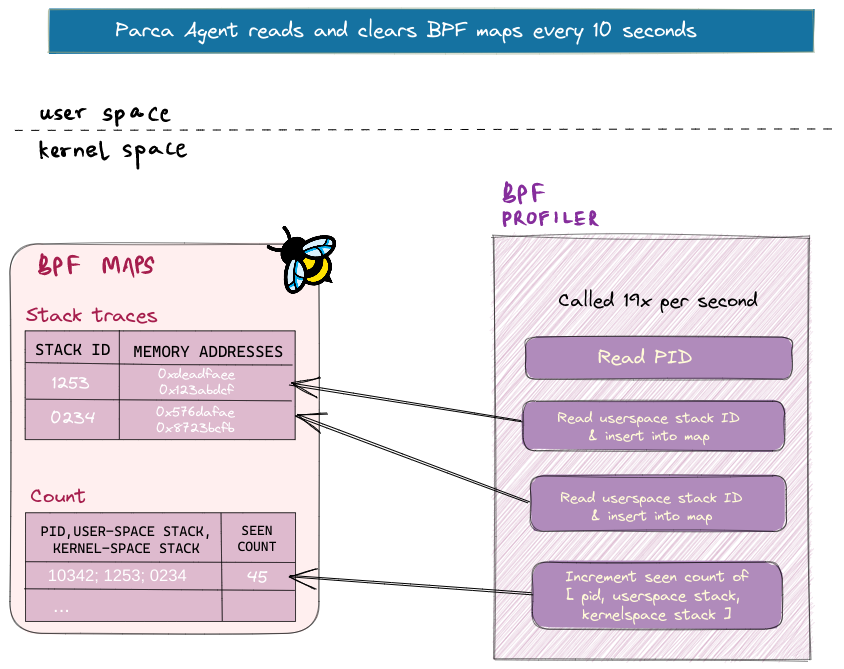
Service/process discovery
The Agent discovers CPU samples for all processes across the host to have an always-on profiler. This system-wide profiling is enabled by attaching the CPU profiler to a single perf event. For 19x per second, the profiler looks to fetch new processes and update associated metadata. A profile is created for every process(or PID) discovered. The Agent also continuously polls for Kubernetes events that are running. Once a containerised process is discovered, a PID is associated with the containerised binary and available pod/cluster metadata attached to it.
eBPF in the agent
Under the hood, the CPU profiler is actually an eBPF program- this is attached to a perf_event for each CPU, specifically the PERF_COUNT_SW_CPU_CLOCK event. This enables us to instruct the kernel to call the BPF program numerous times every second without a very high overhead.
eBPF programs collect the raw data in kernel space. BPF maps are used to communicate this data to user space. These maps are created and populated by the profiler and further processed to give us stack traces.
These are the two BPF maps used by the Parca Agent:
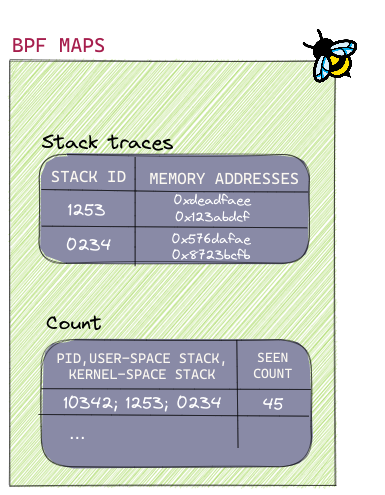
- Stack traces
- The stack traces map comprises the stack trace ID as the key and the memory addresses that point to the code executed - i.e. the stack trace address - as the value.
- Counts
- The counts map comprises the triple of PID, user-space stack ID, and kernel-space stack ID as the key and the frequency with which the same stack trace ID is observed is the value.
Once the Agent accesses the data in user space, the maps are flushed every 10 seconds to enable the collection of new data.
Symbolisation
Stack traces collected by the profiler are memory location addresses- these need to be resolved to human readable symbols for us to utilise them. We obtain two types of symbols:
- Kernel symbols
- Kernel stack traces are immediately symbolized by the Parca Agent since the Kernel can have a dynamic memory layout (for example, loaded eBPF programs in addition to the static kernel pieces). This is done by reading symbols from `/proc/kallsyms` and resolving the memory addresses accordingly.
- Application symbols
- Binaries or shared libraries/objects that contain debug symbols can have their symbols extracted and uploaded to the remote server. The remote Parca server can then use it to symbolize the stack traces at read time rather than in the agent. This also allows debug symbols to be uploaded separately if they are stripped in a CI process or retrieved from upstream public symbol servers such as debuginfod.
An issue that frequently arises while symbolising applications is the lack of debug information in the application binary - often the case when binaries are compiled without frame pointers. To fix this, we extended our symbolizer to generate unwind tables from DWARF debug information using the .eh_frame section of a binary. Although still experimental, the DWARF-based stack walking can be used by enabling the `--experimental-enable-dwarf-unwinding -debug-process-names="node"` flag.
Supported language profiles
Parca agent currently supports CPU profiling for all compiled languages like C/C++, Rust, Go, etc.
Symbolisation for some JIT compilers like JVM, Erlang/Elixir, and NodeJS can be achieved by using `perf-maps`. Our parca-demo repo has some great examples for showcasing profiling with Parca using `perf-maps`. Out-of-the-box support for dynamic languages symbolisation is on our current roadmap and related issues are being tracked here.
Additional resources
- Worried about giving privileged permissions to an eBPF based, in-kernel binary? We have got you covered.
- There are several other flags to make running the agent more configurable. Check them out here.
- Want to contribute to Parca Agent? Start here or say hi on Discord!